


真声VS. AI合成:你真的能分辨出来吗?港中文滕相斌博士联合天津大学重磅发文:短时训练即可激活大脑“反AI语音”识别机制
本研究由天津大学、天津市脑机交互与人机共融海河实验室,以及香港中文大学心理学系和大脑与认知研究所的研究人员共同完成。通讯作者为香港中文大学的滕相斌博士。
随着人工智能(AI)技术的快速发展,如今我们手机里的语音助手、导航播报,很多都已经由AI生成,声音听起来越来越自然,说明文本转语音(TTS)系统已经能够生成与真人语音几乎无法区分的合成语音。这项技术虽然为视力障碍人士等群体带来了便利,但也引发了严重的社会风险,尤其是在诈骗和欺诈领域,不法分子可以利用它来伪造熟人声音进行犯罪。因此,如何帮助听众有效辨别AI克隆语音与真人声音,成了一个既紧迫又现实的问题。
人类天生就具备出色的嗓音识别能力,能够利用音高、节奏、共鸣等独特的声学特征来辨认说话者。然而,现代AI语音合成算法虽然能高度模仿这些特征,但其背后的生成机制(基于统计模型和算法)与人类(基于生理发声过程)有着本质区别。研究团队推测,AI语音与人声之间必然存在声学差异,但人类听觉系统可能尚未学会在行为层面利用这些差异,导致我们在听感上难以区分,这类似于“异谱同色”现象——物理上不同的刺激,由于我们感知系统的局限性,听起来却一模一样。
基于知觉学习的理论,研究团队提出核心假设:虽然人们的听觉系统初始是为处理人声而“调谐”的,但通过短期的知觉训练,可能能够重新“调谐”,使其对AI与人声之间的细微声学差异变得敏感。本研究旨在探究一个简短、生态效度高且易于实施的训练,是否能增强听者对AI生成语音的辨别能力,并结合脑电图(EEG)技术,揭示其背后的神经机制。

为验证研究假设,研究团队设计了一套结合行为测试与神经信号记录的实验方案。被试为35名普通话母语健康成年人,最终30名(15名女性)的数据纳入分析,所有被试均无听力障碍或神经疾病史,且对实验中所用说话者的声音不熟悉。
实验材料方面,人声材料由三名普通话母语者在隔音室内录制了67个标准测试句和四个故事摘要;AI生成语音则使用当时最先进的开源TTS工具GPT-SoVITS合成,分为未微调(AI-NF,直接使用模型生成)和微调(AI-FT,基于一名说话者的部分录音对模型微调生成,能更逼真地模仿目标说话者)两类。声学分析显示,在5.4–11.7 Hz频段,AI语音与人声存在显著的声学差异。
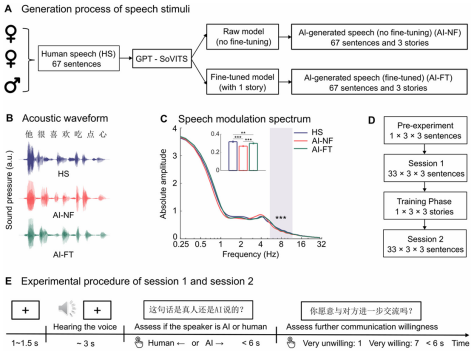
图1 刺激生成过程及实验范式设计
实验中,脑电信号采用64通道脑电系统(eego mylab, ANT Neuro)在隔音、灯光昏暗的实验室内完成采集。数据分析方面,行为数据采用信号检测论计算敏感性指标(![]() )与反应偏向;脑电数据则通过时间响应函数分析神经实时追踪差异,并结合频谱分析与解码分析从不同维度考察神经反应。
)与反应偏向;脑电数据则通过时间响应函数分析神经实时追踪差异,并结合频谱分析与解码分析从不同维度考察神经反应。

图2 实验所用64通道脑电采集系统
研究结果
行为结果:训练未能有效提升辨别能力,但改变了反应策略
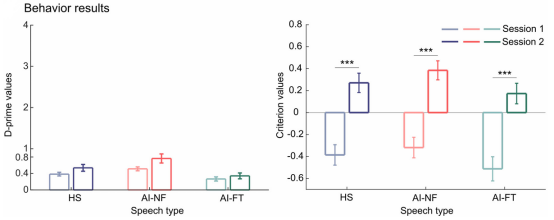
图3行为分析结果
行为学分析显示,无论训练前后,被试在区分真人语音与AI语音(包括微调与非微调版本)时,敏感性指标![]() 均处于极低水平(接近0),表明其几乎无法准确辨别两类语音。重复测量方差分析发现,训练轮次(前测vs.后测)的主效应不显著,说明简短训练未带来行为辨别能力的显著提升。然而,训练显著改变了被试的反应偏向:训练后,所有语音类型下的c值均显著增大,表明被试从训练前倾向于将语音判断为“信号”(真人)的策略,转变为训练后更保守的策略,即更倾向于将语音判断为“非信号”(AI)。这一结果提示,虽然训练未提升辨别敏感性,但参与者学会了调整判断阈值。
均处于极低水平(接近0),表明其几乎无法准确辨别两类语音。重复测量方差分析发现,训练轮次(前测vs.后测)的主效应不显著,说明简短训练未带来行为辨别能力的显著提升。然而,训练显著改变了被试的反应偏向:训练后,所有语音类型下的c值均显著增大,表明被试从训练前倾向于将语音判断为“信号”(真人)的策略,转变为训练后更保守的策略,即更倾向于将语音判断为“非信号”(AI)。这一结果提示,虽然训练未提升辨别敏感性,但参与者学会了调整判断阈值。
神经层面:训练诱导出显著的神经分化
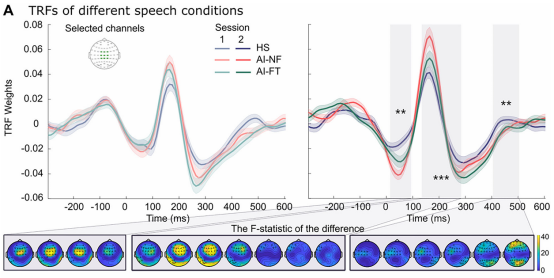
图4 训练后三种语音类型在中央电极簇(FCz,FC1,FC2,Cz,C1,C2,CPz,CP1,CP2)上的平均时间响应函数波形
时间响应函数分析揭示了训练前后的关键神经变化。在训练前,三种语音类型(HS, AI-NF, AI-FT)诱发的时间响应函数波形在统计上无显著差异。但在训练后,基于聚类的置换检验识别出三个显著的时间-空间聚类,分别位于刺激开始后约55毫秒、210毫秒和455毫秒。这表明,短时训练使大脑听觉系统在早期和晚期加工阶段,对真人语音与AI语音产生了显著的神经反应差异。空间分布上,早期成分在左侧前部电极(如F3)差异更明显,而晚期成分则表现为更广泛的额-中央-顶叶分布。
其他神经分析结果
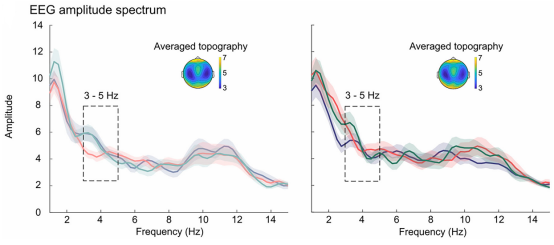
图5 训练后三种语音类型在中央电极簇上的平均功率谱(1-15 Hz)
与时间响应函数结果不同,EEG频谱分析(1-15 Hz)在训练前后均未发现三种语音类型之间存在任何显著差异的聚类。即便在声学分析已证实存在差异的5.4-11.7 Hz频段进行聚焦分析,也未观察到显著的神经功率调制。此外,基于支持向量机的解码分析,利用全脑61个电极的空间模式对语音类型进行分类,结果显示分类准确率始终在随机水平(约50%)附近波动,且在各时间点经多重比较校正后均未达到显著水平。这表明,从脑电信号的总体功率或空间地形模式上,无法有效区分人声与AI语音。
结论与讨论
本研究的核心发现是“神经-行为分离”:短时知觉训练虽未显著提升人们分辨AI语音与真人语音的行为能力,却让大脑在听觉加工的早期和晚期阶段,对两类语音产生了清晰的神经反应差异。这说明大脑其实能“听出”其中的细微差别,但这种精细的神经编码尚未转化为稳定的行为判断。这一现象印证了“反向层级理论”,即早期感觉系统本就保留着最精细的刺激信息,知觉训练首先作用于这些基础层面,而要真正服务于行为判断,可能还需要更长时间或更有针对性的训练。
研究同时提示,现代AI语音在长时统计特征上虽高度拟人,但在毫秒级的时域动态上仍有缺陷,而时间响应函数恰好能捕捉大脑对这些动态细节的追踪,因此比频谱分析更敏感。本研究为应对AI语音滥用风险提供了积极信号:人类大脑天生具备区分AI与人声的神经潜能,通过适当训练即可激活。未来研究需进一步探索长期熟悉度、语境丰富度对辨别能力的影响,并精准识别AI与人声的关键声学差异,为反诈骗工具开发与政策制定提供科学依据。
Citation:Yang, J., Jiang, H., Bai, Y., Ni, G., & Teng, X. (2026). Short-term perceptual training modulates neural responses to deepfake speech but does not improve behavioral discrimination. eNeuro, 13(3), ENEURO.0300-25.2026.
DOI: 10.1523/ENEURO.0300-25.2026
通讯作者:滕相斌,香港中文大学

